论文速读<一>:关系抽取与提示学习
论文速读<一>:关系抽取与提示学习
论文速读系列为对论文的核心思想进行快速抓取,仅记录论文的Key Idea。本期为论文速读系列的第一期,选取了5篇近期知识图谱领域的关系抽取相关论文。
Key Idea
Enriching pre-trained language model with entity information for relation classification.[1]
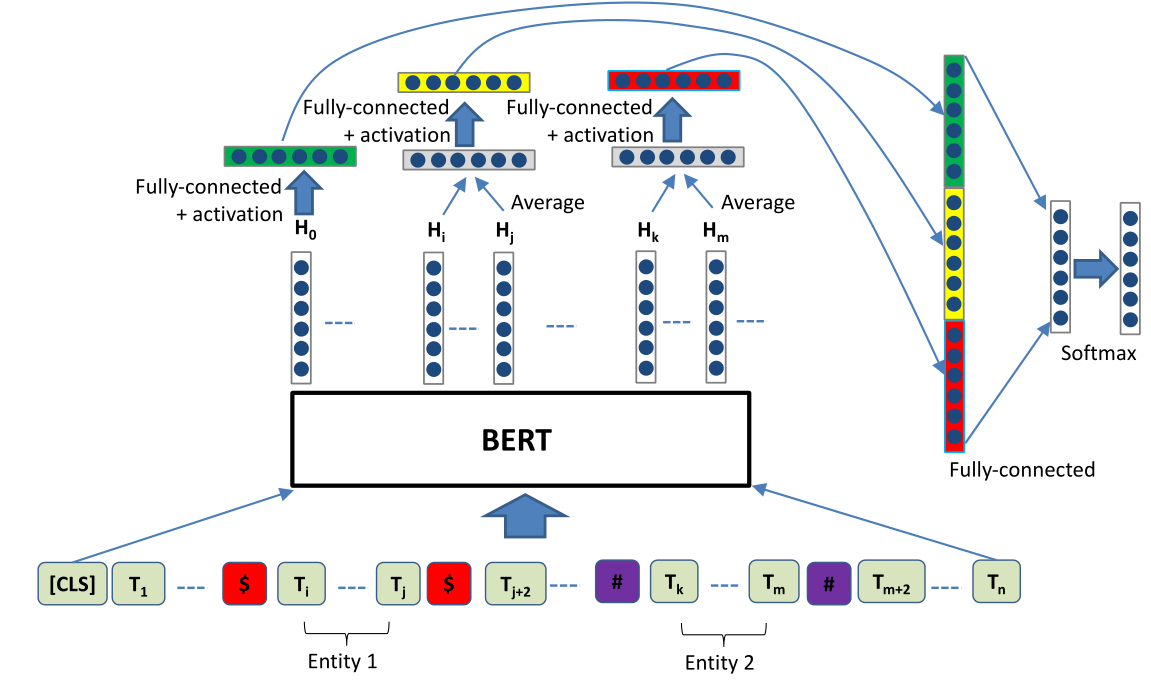
R-Bert模型的框架如上图所示,其主要思路就是对每个句子的关系的头部放一个分类头,并在2个实体出使用特殊标记,放进预训练好后的Bert中,在输出中,实体所对应的embedding做一个平均值,和分类头的embedding分别经过3个MLP,最后做一个拼接,输出到softmax中去,进行分类。
Relation classification with entity type restriction.
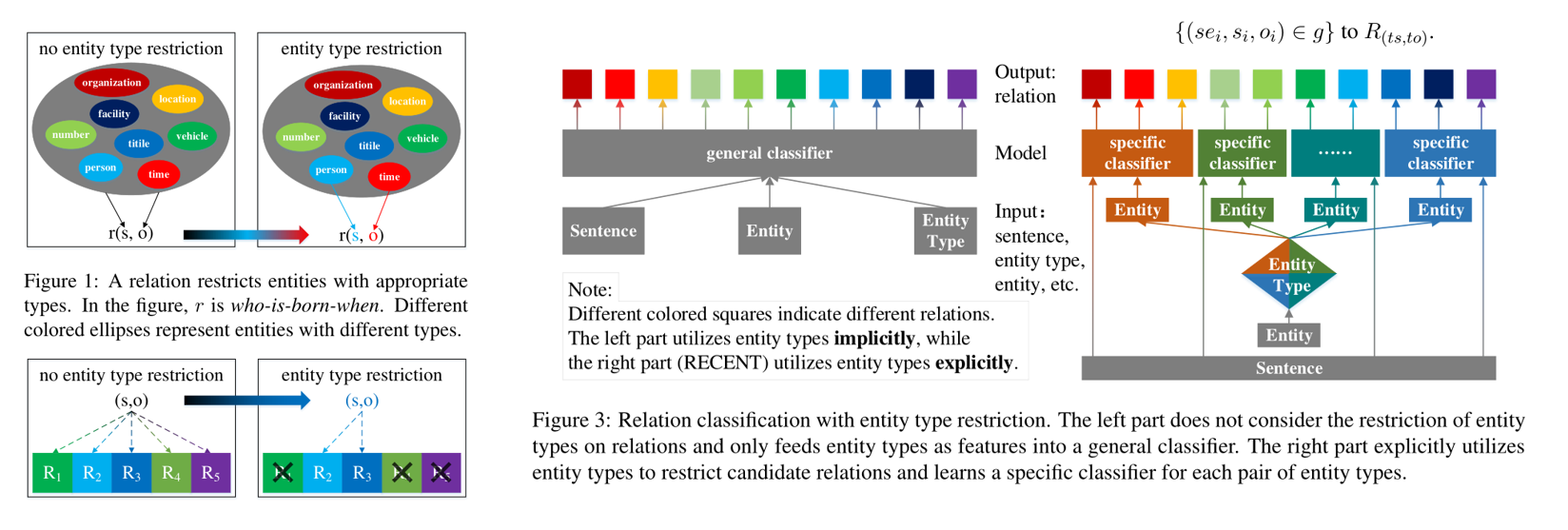
该论文事实上是提出了一个算法无关的流程。
传统的关系抽取是将句子、实体以及实体类型一起丢进一个分类器中,然后输出关系的类别。但假如根据实体的类型可以一定程度上的筛掉一些不可能的关系。因此区别于传统的做法,它首先将实体丢进一个分类器,然后获得其类别之后,根据实体的类型去训练专用的分类器,最后句子一起输入到这个专用分类器中,输出对应的类别。
Ptr: Prompt tuning with rules for text classification.
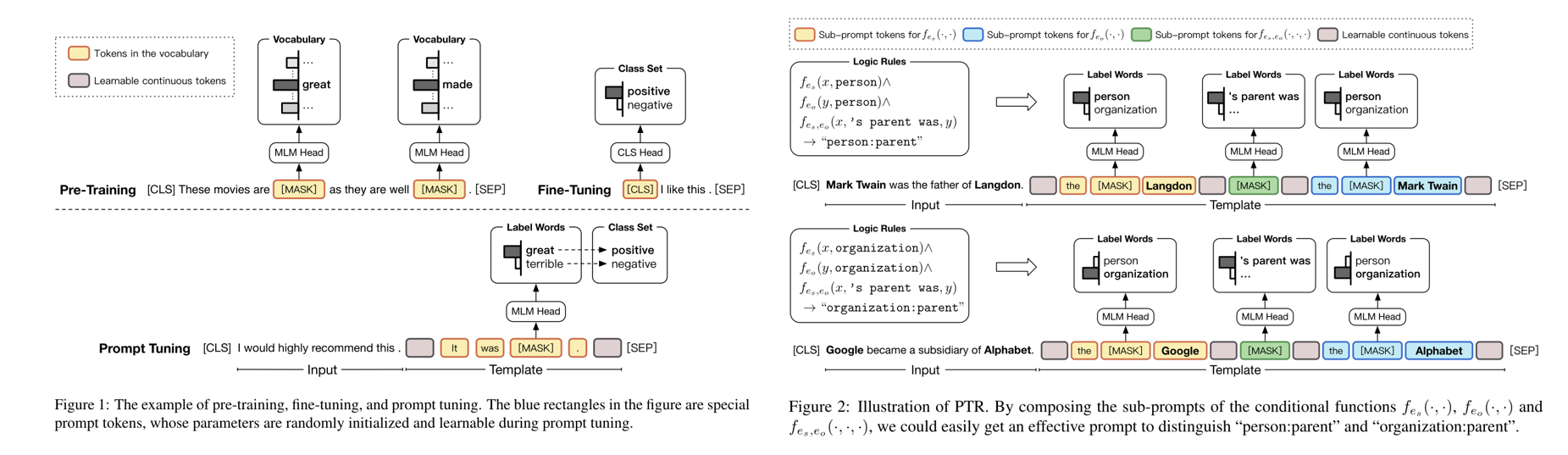
该论文提出了一种提示学习的方法对文本进行分类。提示学习就是在Fine Tuning的时候加一个模板化的提示,这样可以使得原问题更贴近于自然语言处理的问题,从而更贴合预训练的自然语言模型。
该论文的模式来源于推理规则,他在Fine Tuning时,在句子的结尾增添提示。给出句子的实体,但对实体的类型和实体间的关系做一个mask。这样可以使得模型能将实体与对应的类型结合起来,推理出他们之间的关系。
Summarization as Indirect Supervision for Relation Extraction
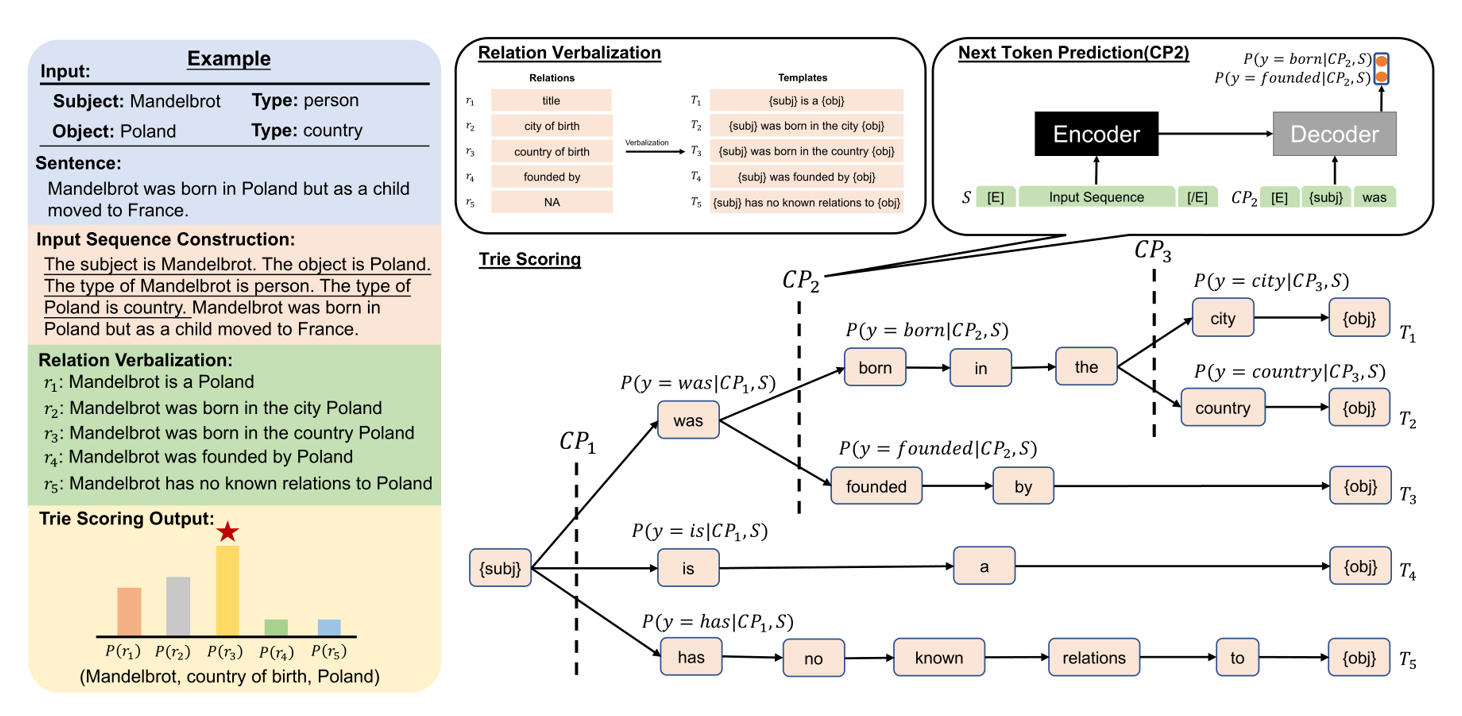
该论文将摘要模型用于关系抽取。
若想要将摘要模型应用在句子的关系抽取上,需要将关系抽取问题转化为摘要问题。直觉上来讲,上游模型的特点和下游任务的关系月紧密,它的效果也会越好。
和通常的提示学习想法类似,它也是对原句子进行模板化改造,只不过将句子转换为一个段落而已。如上图所示,所谓的段落就是,加上“主语是。。。”,“谓语是。。。”这样的信息。
由于摘要模型输入是一个段落,输出是一个句子,而不是一个标签。因此输出的标签也应当做一个改造。改造的方式也很简单,比如”city of birth”就改在为”subj was born in the city obj”。需要注意的是,主语放在句子开头,宾语放在句子结尾。这是方便后面的预测。
其预测过程是构造一棵字典树,由于所有的句子主语放在开头,所以他们有同一个根结点。从根据结点出发,每次遇到一个分叉就使用decoder进行预测,给出每个分叉的概率。最后每个类别的概率,就是跟结点到叶结点的路上所有概率的乘积。选择最大的就是输出。
Prefix-tuning: Optimizing continuous prompts for generation.

提示学习所用的提示模板往往是一个个离散的词。该文章提出了一种将离散词嵌入到连续空间中去,比如使用2个向量,使其起到提示的效果。
参考资料
- Shanchan Wu and Yifan He. 2019. Enriching pre-trained language model with entity information for relation classification. In Proceedings of the 28th ACM international conference on information and knowledge management, pages 2361–2364. ↩
- Shengfei Lyu and Huanhuan Chen. 2021. Relation classification with entity type restriction. In Findings of the Association for Computational Linguistics: ACLIJCNLP 2021, pages 390–395, Online. Association for Computational Linguistics. ↩
- Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. 2021. Ptr: Prompt tuning with rules for text classification. arXiv preprint arXiv:2105.11259. ↩
- Lu K, Hsu I, Zhou W, et al. Summarization as Indirect Supervision for Relation Extraction[J]. arXiv preprint arXiv:2205.09837, 2022. ↩
- Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics. ↩